Introduction
近年、人工知能の進歩、特にChatGPTのような大規模言語モデルは、様々な分野で目覚ましい能力を示している [1,2]。さらに、先日GPT-5のような最先端モデルも登場し、今尚進歩し続けている [3]。しかしながら、放射線技術学におけるChatGPTの可能性は検証されつつあるものの、未だ十分とは言えない [4,5]。本記事では、ChatGPTが診療放射線技師国家試験を解く能力を調査し、教育支援システムとしての可能性を評価する。
Materials and Methods
本記事では、診療放射線技師国家試験の問題を用いて、GPT-4oとGPT-5ベースのChatGPTの性能を評価した。まず、問題には画像問題と文章問題があるため、厚生労働省のホームページのPDFから問題と正答を取得した [6]。問題と必要であれば画像、選択肢を与えて、ChatGPTからは答えの選択肢を出力するように実施した。研究の概要を図1に示す。
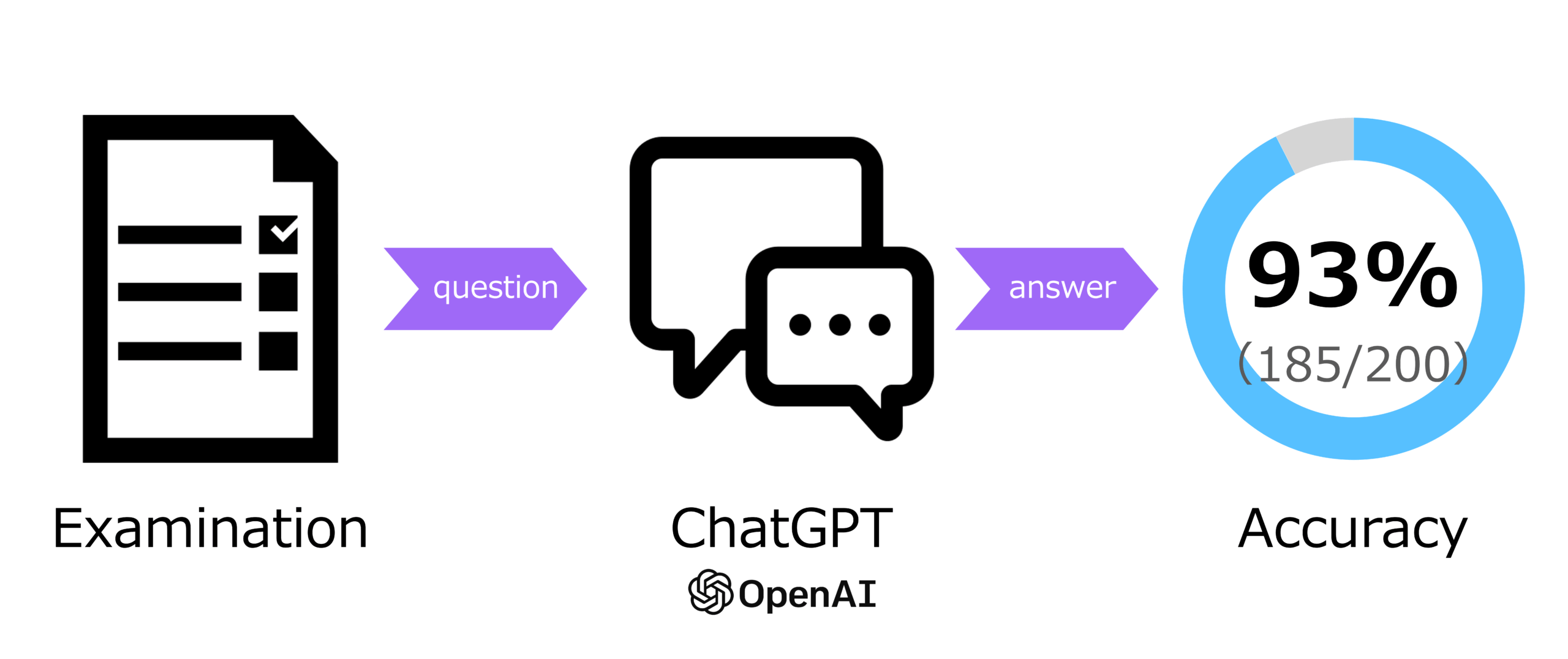
2025年2月20日に実施された第77回診療放射線技師国家試験の問題を使用した。全部で200問が取得された。そのうち、27問が問題文に画像を含むものであった。
ChatGPTは、APIを使用して画像および文章を入力した。
Results
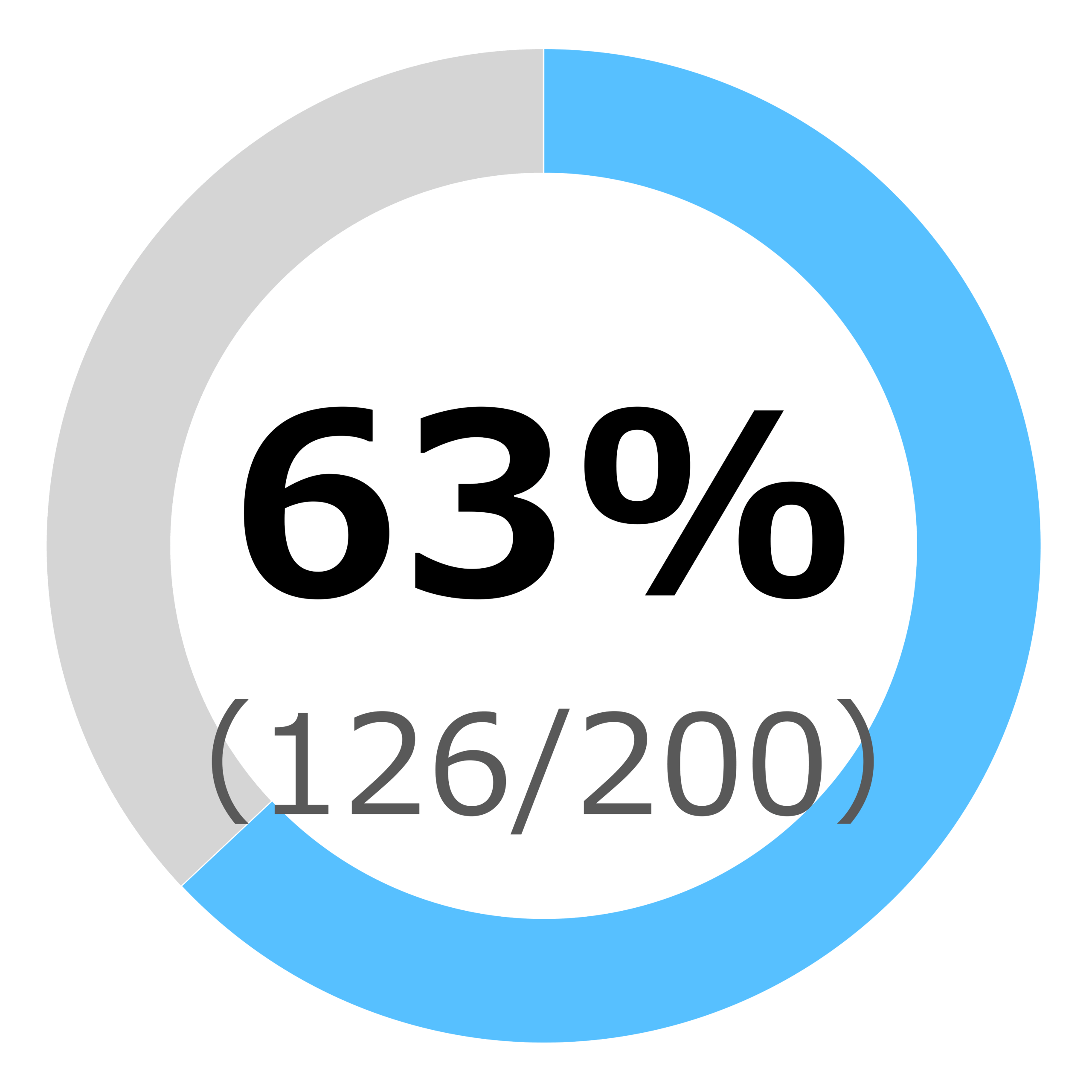
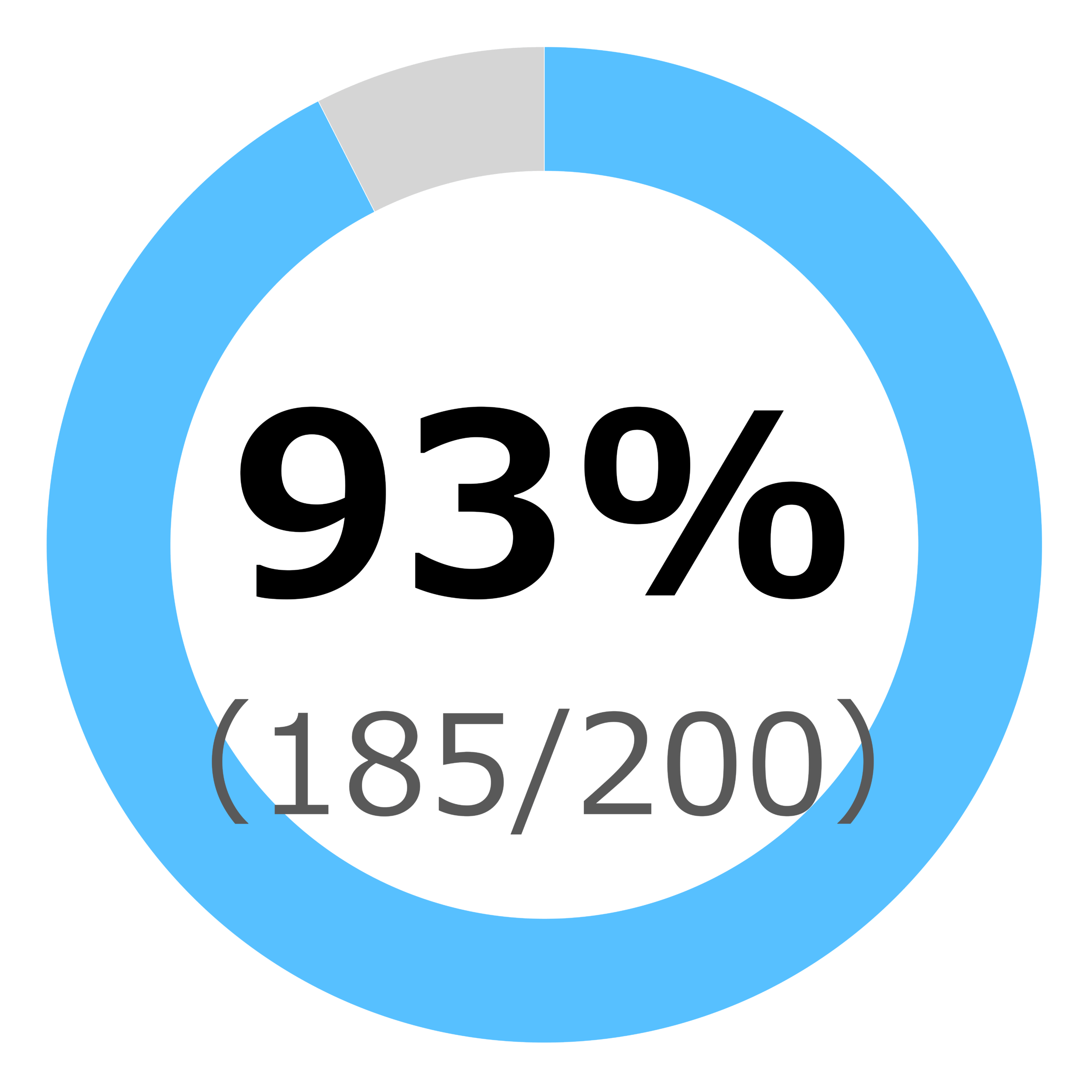
結果を図2aおよび図2bに示す。GPT-4oベースのモデルは、正解率63%(126/200)、GPT-5ベースのモデルは、正解率92.5%(185/200)であった。
科目ごとの正解率を表1に示す。※ 77回から試験科目は従来の14科目から11科目に変更となった。出題総数は従来の200問から変更はない。
全ての科目でGPT-5がGPT-4oを上回る結果となった。

続いて、画像問題に対する正解率を表2に示す。画像問題に対しては、両モデルで共に60%(国家試験合格ライン)を超えない結果であったが、GPT-5がGPT-4oを上回る結果となった。

Discussion
本研究では、第77回診療放射線技師国家試験の200問(うち27問が画像問題)を用いて、GPT-4oとGPT-5ベースのChatGPTの性能を比較した。その結果、GPT-5は正解率92.5%(185/200)とGPT-4oの63%(126/200)を大きく上回った。科目別の分析でも、すべての科目でGPT-5がGPT-4oを上回り、とくに基礎医学大要・理工学・放射線科学・放射線治療技術学・放射線安全管理学などで顕著な改善が認められた。これは、GPT-5が最新の学習データや推論アルゴリズムの改善により、専門用語や概念理解、試験形式への適応力を高めている可能性を示唆する。
一方、画像問題に関しては、GPT-4oが41%(11/27)、GPT-5が59%(16/27)といずれも合格ラインの60%に満たなかった。GPT-5は確かに向上しているが、テキスト主体の問題に比べると依然として大きな性能差があり、視覚情報の解釈や臨床画像に特有のパターン認識が現状の大規模言語モデルおよび大規模マルチモーダルモデルの課題であることが明らかになった。この傾向は先行研究とも一致しており、ChatGPTなどのLLMは文章問題に比べて画像問題の正答率が低いことが報告されている [7]。
本研究の結果から、GPT-5は放射線技術学の文章問題に対しては、合格水準を上回る十分に高い性能を発揮でき、教育支援システムとしての活用可能性が高いと考えられる。例えば、模擬試験や復習教材の自動生成、解説の提示などに応用可能性がある。ただし、画像診断領域や画像機器学など、画像認識を必要とする出題形式では正答率の限界があり、そのまま臨床判断支援に利用することは時期尚早である。
本研究にはいくつかの限界がある。第一に、使用した問題は1年分(第77回試験)のみであり、試験年度や問題傾向の変動を考慮できていない。第二に、画像問題の提示は国家試験PDFから抽出した静止画像であり、実際の試験環境や高解像度表示、複数枚画像の連続提示といった条件を再現できていない。第三に、ChatGPTの回答は出力された選択肢のみで評価しており、理由付けや解答根拠の正確性は評価していない。
今後は、複数年度の試験データや類似形式の模擬問題を用いた評価により、年度間の性能一貫性を検証する必要がある。また、画像問題については、より高解像度データや臨床に近い表示環境での性能測定、さらに画像特徴の説明生成能力の検証が求められる。これらを通じて、LLMが放射線技術学教育や試験対策のみならず、将来的な臨床支援へと活用可能かを明らかにしていくことが重要である。
References
[1] Ray, P. P. (2023). ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet of Things and Cyber-Physical Systems, 3, 121–154. https://doi.org/10.1016/j.iotcps.2023.04.003
[2] Clusmann, J., Kolbinger, F.R., Muti, H.S. et al. The future landscape of large language models in medicine. Commun Med 3, 141 (2023). https://doi.org/10.1038/s43856-023-00370-1
[3] OpenAI. (2025, August 7). GPT-5 のご紹介. OpenAI. Retrieved [2025/8/14], from https://openai.com/ja-JP/index/introducing-gpt-5/
[4] Al-Naser, Y., Halka, F., Ng, B., Mountford, D., Sharma, S., Niure, K., Yong-Hing, C., Khosa, F., & Van der Pol, C. (2025). Evaluating artificial intelligence competency in education: Performance of ChatGPT-4 in the American Registry of Radiologic Technologists (ARRT) radiography certification exam. Academic Radiology, 32(2), 597-603. https://doi.org/10.1016/j.acra.2024.08.009
[5] Duggan, R., & Tsuruda, K. M. (2024). ChatGPT performance on radiation technologist and therapist entry to practice exams. Journal of Medical Imaging and Radiation Sciences, 55(4), 101426. https://doi.org/10.1016/j.jmir.2024.04.019
[6] 厚生労働省. (2025年4月28日). 第77回診療放射線技師国家試験問題および正答について. 厚生労働省. Retrieved [2025/8/14], from https://www.mhlw.go.jp/seisakunitsuite/bunya/kenkou_iryou/iryou/topics/tp250428-06.html
[7] Duggan, R., & Tsuruda, K. M. (2024). ChatGPT performance on radiation technologist and therapist entry to practice exams. Journal of Medical Imaging and Radiation Sciences, 55(4), 101426. https://doi.org/10.1016/j.jmir.2024.04.019